Value of a Service Mesh
Learn more about service mesh fundamentals in The Enterprise Path to Service Mesh Archictures (2nd Edition) - free book and excellent resource which addresses how to evaluate your organization’s readiness, provides factors to consider when building new applications and converting existing applications to best take advantage of a service mesh, and offers insight on deployment architectures used to get you there.
Service meshes provide visibility, resiliency, traffic, and security control of distributed application services.
Observability
Many organisations are attracted to the uniform observability that service meshes provide. There is no such thing as a fully healthy complex system. Service-level t elemetry sheds light on difficult-to-answer questions like why your requests are slow to respond. It's quite simple to figure out when a service is down, but figuring out where it's slow and why is a different story.
Service meshes allow both black-box (observing a system from the outside) and white-box (monitoring a system from the inside) monitoring of service-to-service communication. To provide white-box monitoring, some service meshes combine with a distributed tracing library. In contrast, other service meshes use protocol-specific filters as a capability of their proxies to provide a deeper level of visibility. The components of the data plane are well-positioned (transparently, in-band) to create metrics, logs, and traces, ensuring uniform and thorough observability across the mesh.
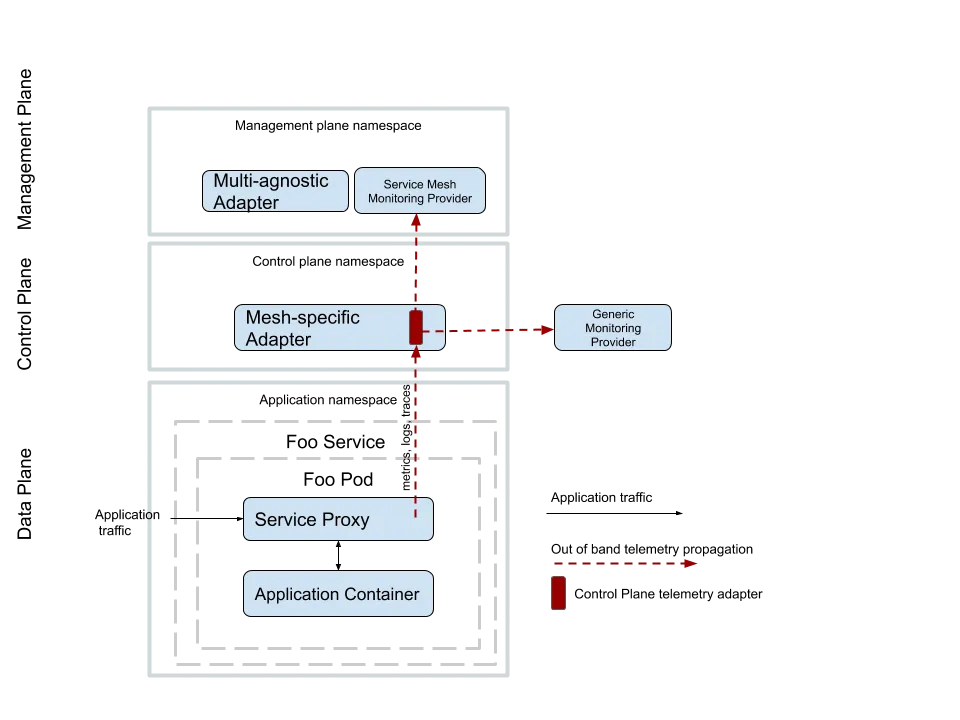
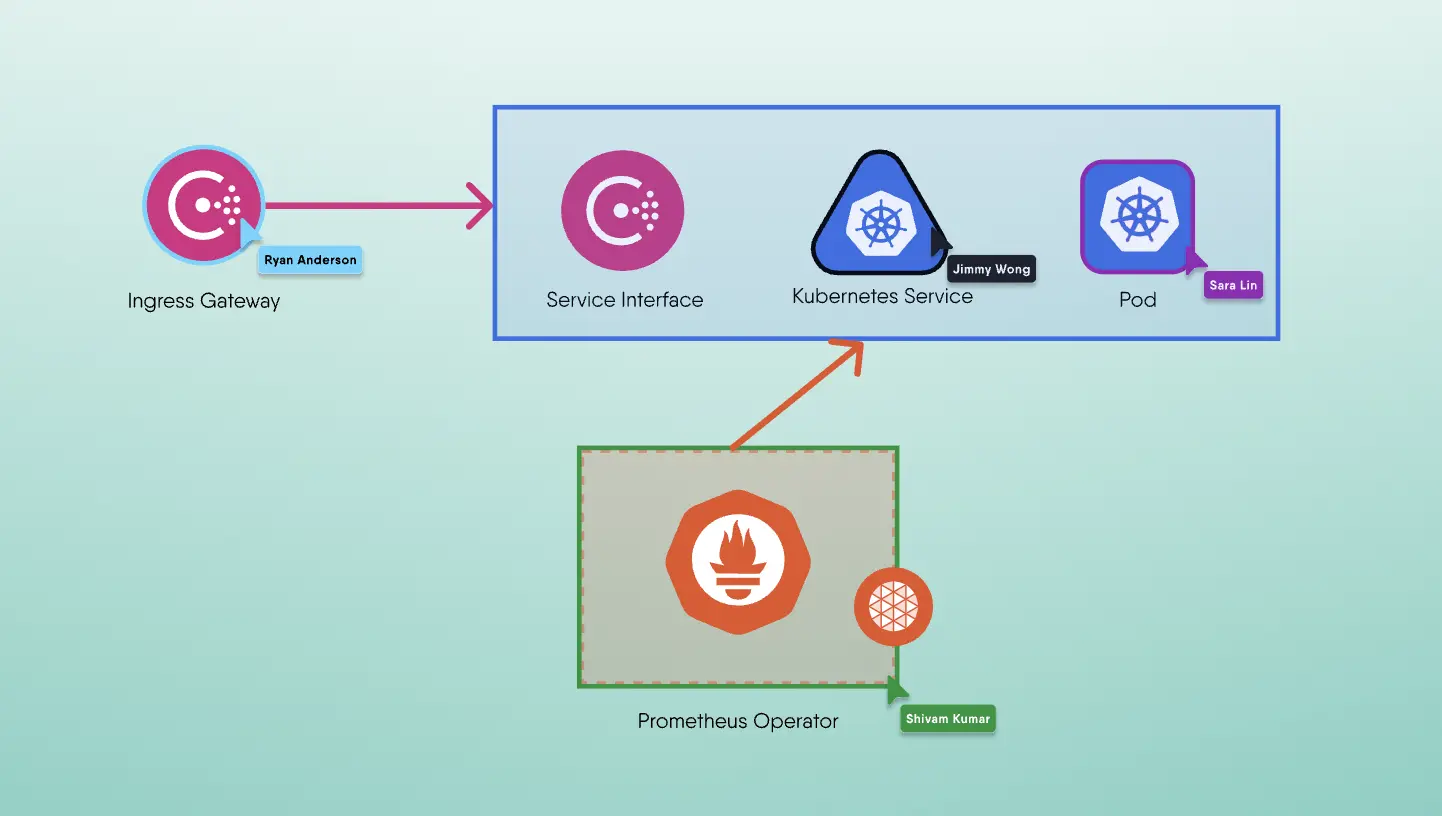
Figure 1: Istio’s Mixer is capable of collecting multiple telemetric signals and sending those signals to backend monitoring, authentication, and quota systems via adapters
Service meshes centralize and assist in solving these observability challenges by providing the following:
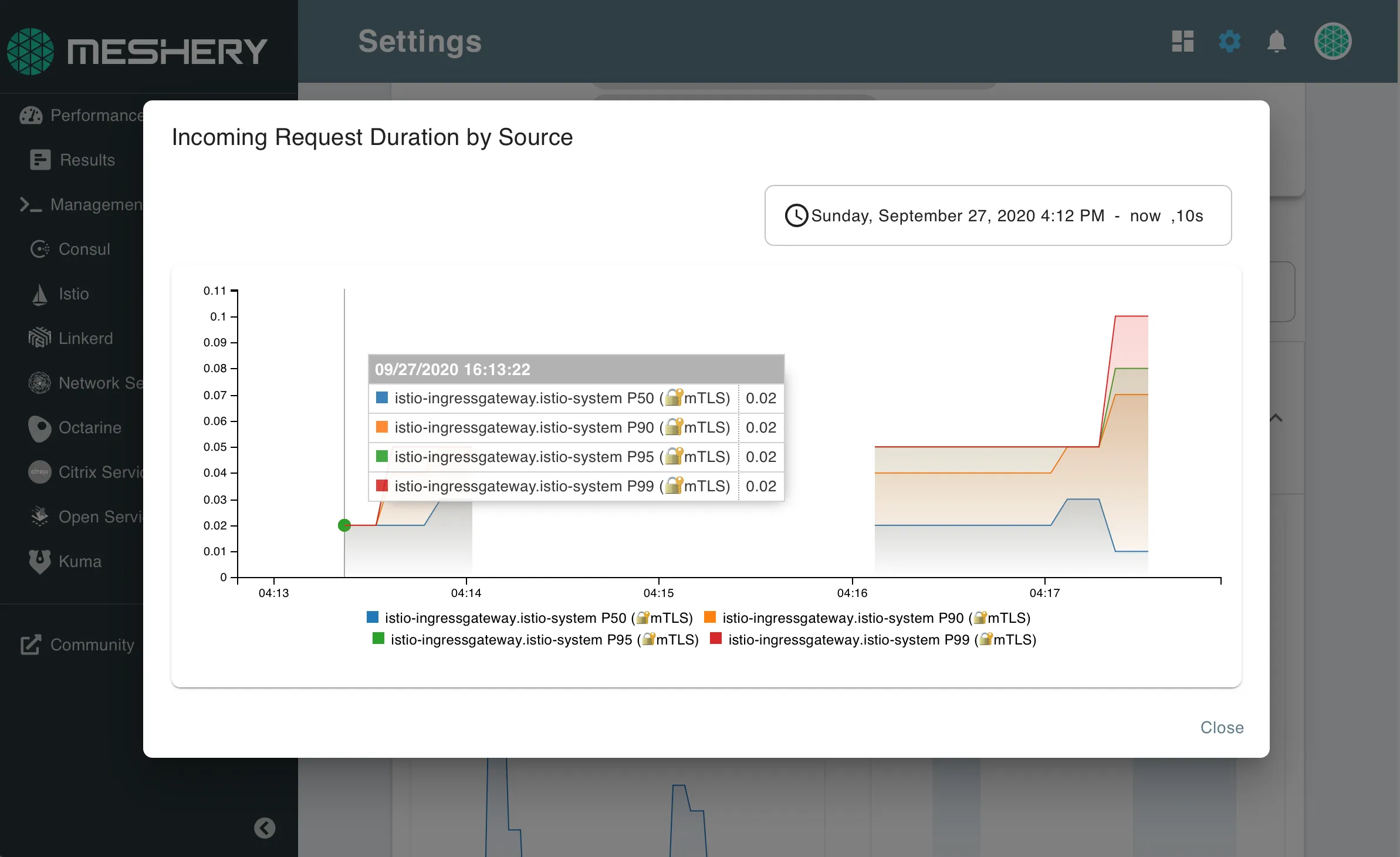
Figure 2: Request metrics generated by Istio and visible in Meshery
- Logging
Logs are used to baseline visibility for access requests to your entire fleet of services. Figure 1 illustrates how telemetry transmitted through service mesh logs include source and destination, request protocol, endpoint (URL), response time, size, and associated response code.
- Metrics
Metrics are used to eliminate the need for the development process to instrument code in order to emit metrics. When metrics are ubiquitous across your cluster, additional insights become available. Consistent metrics allow for things like autoscaling to be automated. Telemetry emitted by service mesh metrics include global request volume, global success rate, individual service responses by version, source and time.
- Tracing
Slow services (as opposed to services that simply fail) are the most difficult to debug without tracing. Imagine manually enumerating and tracking all of your service dependencies in a spreadsheet. Dependencies, request volumes, and failure rates are visualised using traces. Service meshes enable incorporating tracing functionality extremely simple with the help of automatically generated span identifiers. The mesh's individual services still must forward context headers. Many application performance management (APM) solutions, on the other hand, need manual instrumentation to extract traces from your services.
Traffic control
Service meshes provide for granular, declarative control over network traffic, such as determining where a request should be routed to perform canary release. Circuit breaking, latency-aware load balancing, eventually consistent service discovery, timeouts, deadlines, and retries are all common resiliency features.
When a request does not return to the client within a certain amount of predefined time, a timeout is used to terminate it. They provide a time restriction on how much time can be spent on an individual request and are enforced at a point after which a response is considered invalid. Deadlines are an advanced service mesh feature that helps minimise retry storms by facilitating feature-level timeouts rather than independent service timeouts. As a request travels through the mesh, deadlines deduct time remaining to handle it at each stage, propagating elapsed time with each downstream service call. Timeouts and deadlines might be considered enforcers of your Service-Level Objectives (SLOs).
You can choose to retry a request if a service times out or is unsuccessfully returned. Retrying the same call to a service that is already under water (retry three times = 300 percent additional service load) can make things worse. Retry budgets (aka maximum retries) offer the benefit of multiple tries but come with a limit to avoid overloading an already a load-challenged service. Some service meshes go even further to reduce client contention by using jitter and an exponential back-off algorithm to calculate the timing of the next retry attempt.
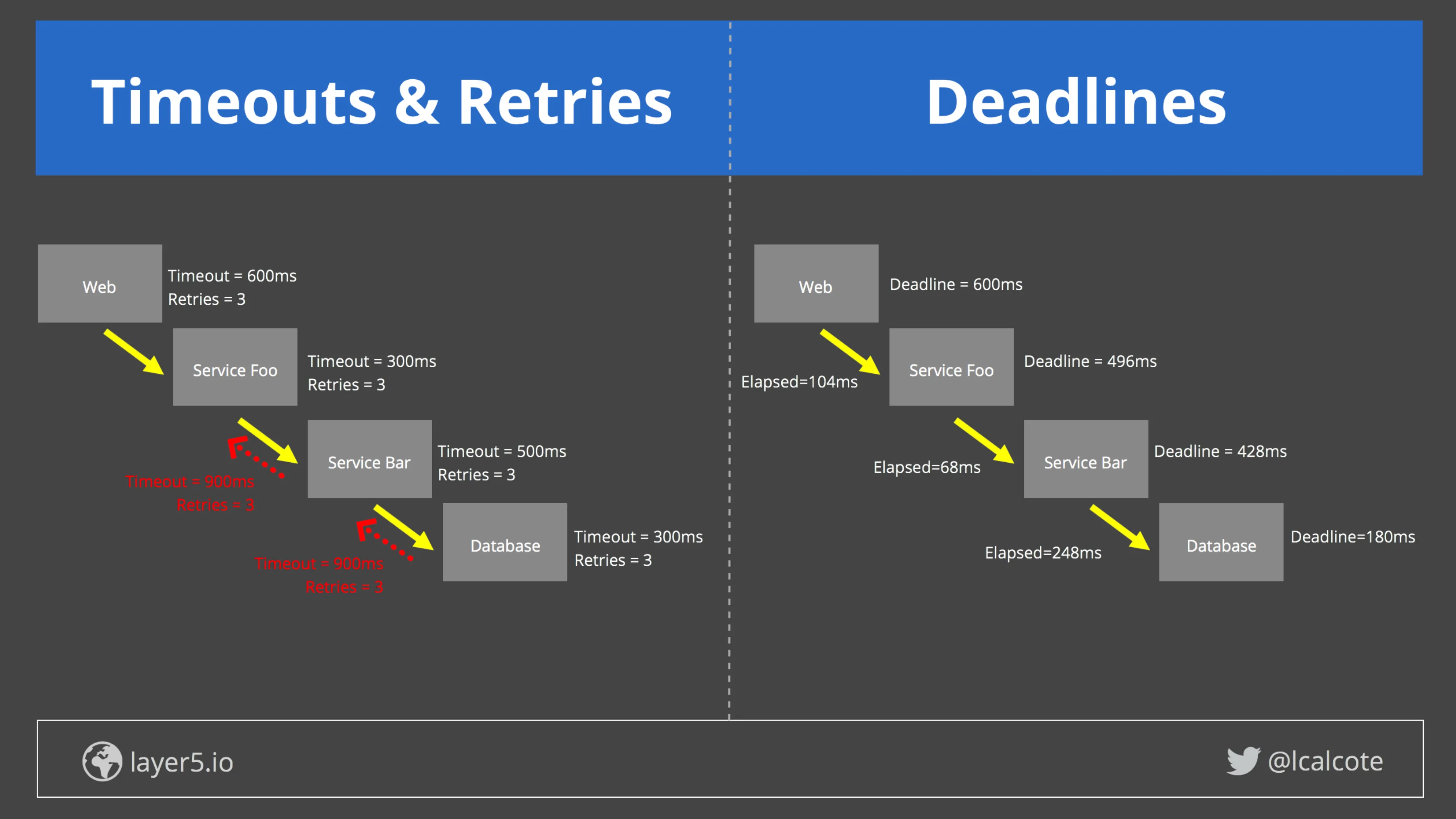
Figure 3:Deadlines, not ubiquitously supported by different service meshes, set feature-level timeouts
You can choose to fail fast and disconnect the service, prohibiting calls to it, rather than retrying and putting more load to the service. Circuit breaking allows users to set configurable timeouts (or failure thresholds) to assure safe maximums and graceful failure, which is common for slow-responding services. When applications (services) are oversubscribed, using a service mesh as a distinct layer to implement circuit breaking minimises undue overhead.
Rate limiting(throttling) is implemented to ensure service stability. When requests by one client surge, the service continues to function smoothly for others. The rate limits are calculated over a period of time. You can also utilise various algorithms, such as a fixed or sliding window, a sliding log, etc. The purpose of rate limits is to ensure that your services are not oversubscribed.
When a limit is reached, well-implemented services commonly adhere to IETF RFC 6585, sending 429 Too Many Requests as the response code, including headers, such as the following, describing the request limit, number of requests remaining, and amount of time remaining until the request counter is reset:
X-RateLimit-Limit: 60
X-RateLimit-Remaining: 0
X-RateLimit-Reset: 1372016266
Quota management (or conditional rate-limiting) accounts for requests based on business requirements instead of limiting rates based on operational concerns. It can be difficult to tell the difference between rate limiting and quota management because both features are handled by the same service mesh capability but are exposed to users in different ways.
Configuring a policy setting a threshold for the number of client requests allowed to a service over time is the canonical example of quota management. User Lee, for example, is on the Free service plan and is allowed upto 10 requests per day. Quota policy imposes consumption limitations on services by keeping track of incoming requests in a distributed counter,often using an in-memory datastore like Redis Conditional rate limits are a powerful service mesh capability when applied based on a user-defined set of arbitrary attributes.
Security
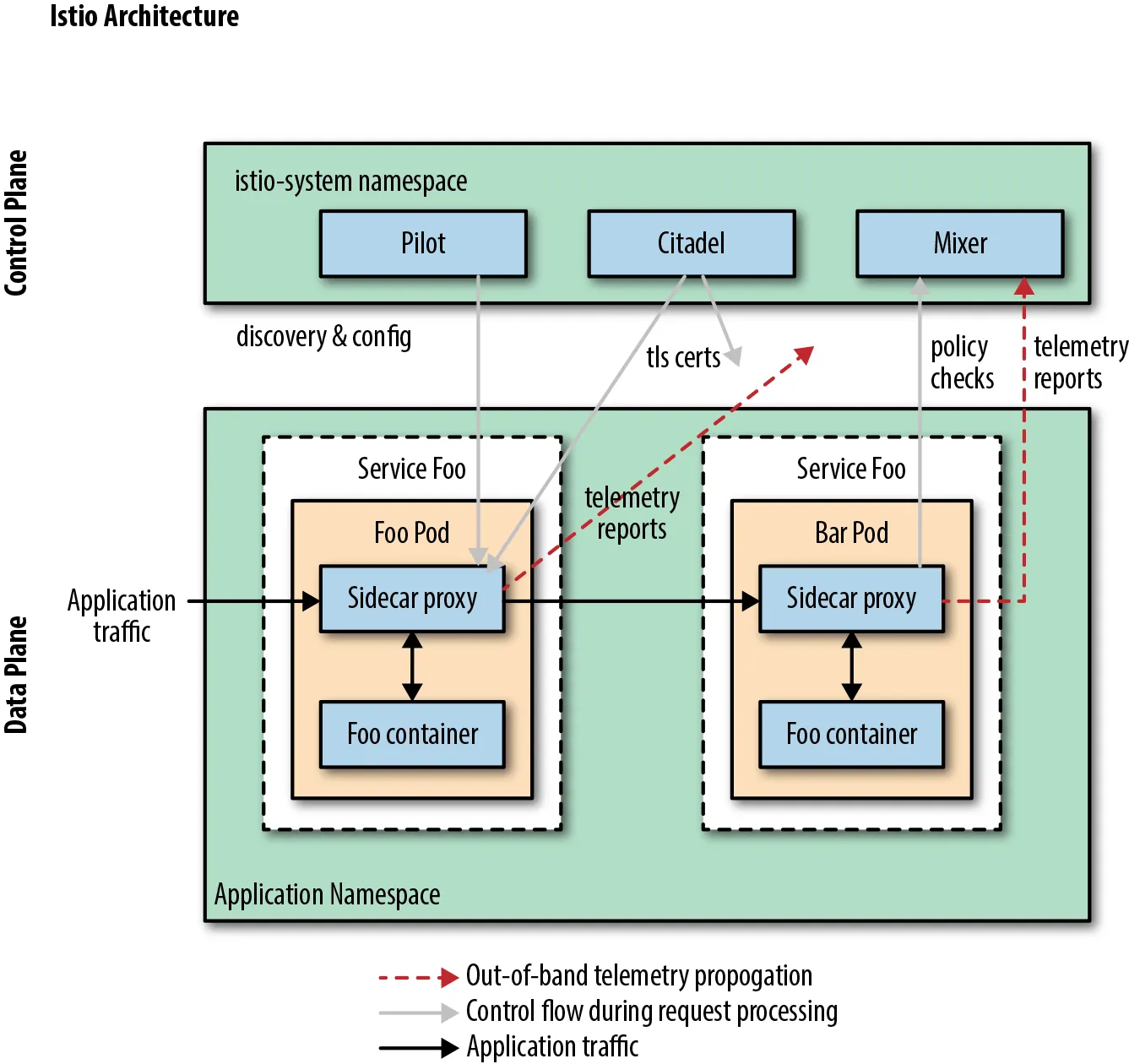
Figure 4: An example of service mesh architecture. Secure communication paths in Istio
For securing service-to-service communication, most service meshes include a certificate authority that manages keys and certificates. Certificates are generated for each service and serve as the service's unique identifier. When sidecar proxies are employed, they assume the identity of the service and perform lifecycle management of certificates (creation, distribution, refresh, and revocation) on its behalf. Local TCP connections are often established between the service and the sidecar proxy, whereas mutual Transport Layer Security (mTLS) connections are typically established between proxies in sidecar proxy deployments.
Internal traffic within your application should be encrypted as a matter of security. The service calls in your application are no longer contained within a single monolith via localhost; they are now exposed over the network. Allowing service calls without TLS on the transport is a recipe for disaster in terms of security. When two mesh-enabled services communicate, they have strong cryptographic proof of their peers. After identities have been established, they are used to create access control policies that determine whether or not a request should be serviced. Policy controls configuration of the key management system (e.g., certificate refresh interval) and operational access control are used to determine whether a request is accepted, based on service mesh employed. Approved and unapproved connection requests, as well as more granular access control parameters like time of day, are identified using white and blacklists.
Delay and fault injection
It's important to accept that your networks and/or systems will fail. Why not introduce failure and verify behaviour ahead of time? As proxies sit in line to service traffic, they frequently support protocol-specific fault injection, which allows you to configure the percentage of requests that should be subjected to faults or network delays. For example, generating HTTP 500 errors might be used to test the robustness of your distributed application's response behaviour.
Injecting latency into requests without a service mesh is a time-consuming procedure, but it is probably a more prevalent problem encountered during operation of an application. Users are far more irritated by slow replies that result in an HTTP 503 after a minute of waiting than by a 503 after a few seconds. The finest element of these resilience testing capabilities is that no application code needs to be changed to make these tests possible. The results of the tests, on the other hand, may prompt you to make changes to the application code.
Using a service mesh, developers spend far less time creating code to cope with infrastructure issues—code that could be commoditized by service meshes in the future. The separation of service and session-layer concerns from application code is manifested as a phenomenon I refer to as decoupling at Layer 5.
A service mesh can be regarded of as surfacing the OSI model's session layer as a separately addressable, first-class citizen in your modern architecture. They are a secret weapon of cloud native systems, waiting to be exploited as a highly configurable work horse.