Considerations of Adopting a Service Mesh
Learn more about service mesh fundamentals in The Enterprise Path to Service Mesh Archictures (2nd Edition) - free book and excellent resource which addresses how to evaluate your organization’s readiness, provides factors to consider when building new applications and converting existing applications to best take advantage of a service mesh, and offers insight on deployment architectures used to get you there.
What are practical steps to adopt a service mesh in my enterprise?
Piecemeal Adoption
Many organisations wish to take advantage of auto-instrumented observability first, taking baby steps toward a full-service mesh after achieving first success and operational comfort, to better understand what's going on across their distributed infrastructure. It's a high-value, relatively safe first step to use a service mesh for its ability to provide enhanced observability. First steps for others might be on a parallel path. For example, a financial organisation might seek improved security with strong identity (per-service certificates) and strong encryption via mutual TLS between each service. Others, on the other hand, may begin with an ingress proxy as a stepping stone to a larger service mesh deployment.
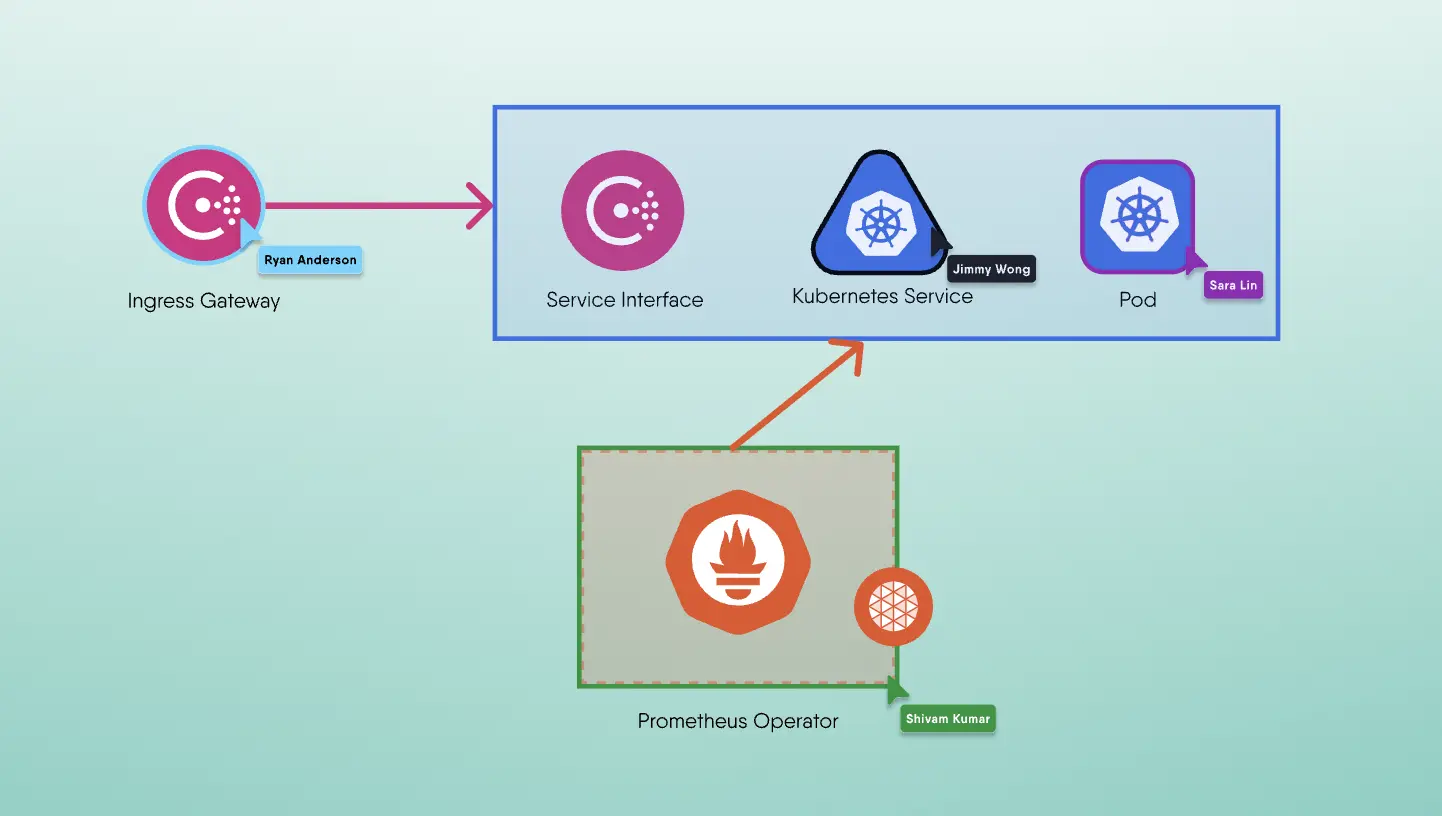
Consider an organisation with hundreds of existing services running on virtual machines (VMs) external to the service mesh that have little to no service-to-service traffic, with practically all traffic flowing from the client to the service and back to the client. Without immediately deploying hundreds of service proxies, this organisation can deploy a service mesh ingress (e.g., Istio Ingress Gateway) to gain granular traffic control (e.g., path rewrites) and detailed service monitoring.
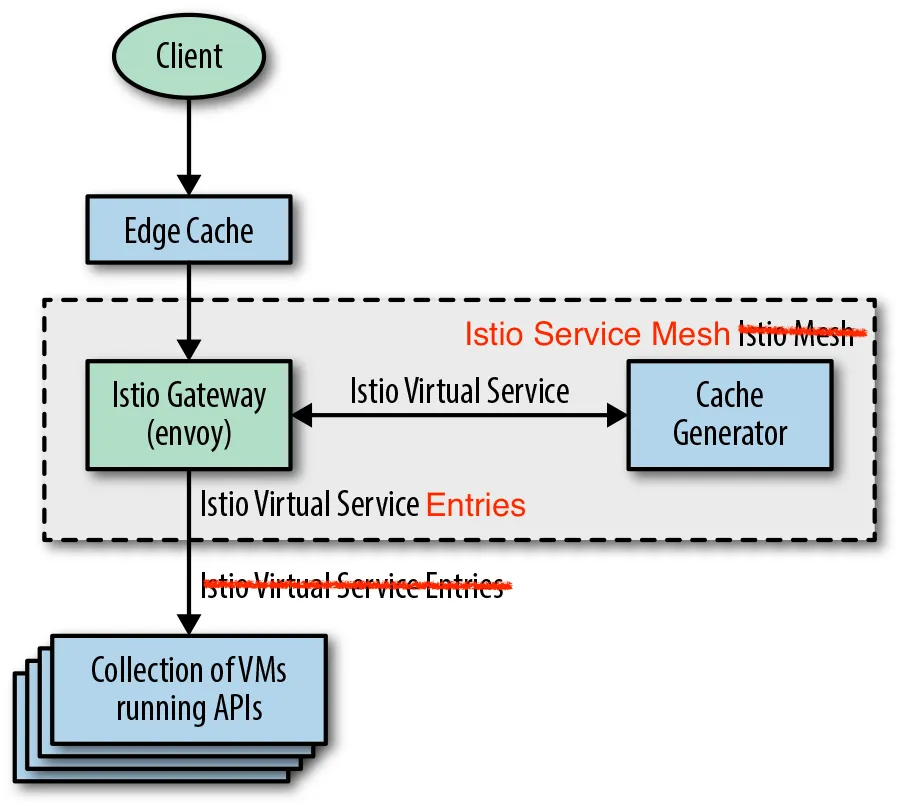
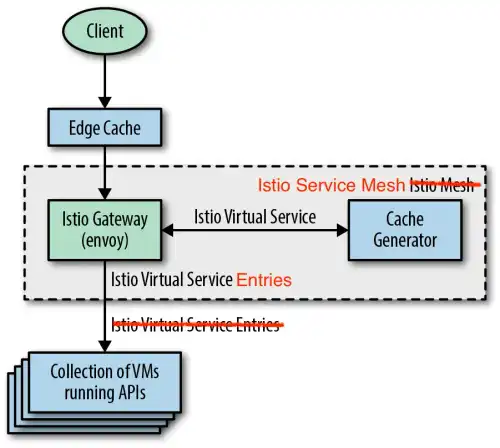
Figure 1: Simple service mesh deployment primarily using ingress traffic control.
Practical Steps to Adoption
Here are two common paths:
- Wholesale adoption of a service mesh, commonly while designing a new application (a greenfield project).
- Piecemeal adoption of some components and capabilities of a service mesh, but not others, commonly while working with an existing application (a brownfield project).
Let's take a look at how the second path manifests itself, because it's the path that most people will face (those with existing services) and the approach that most organisations take. In this method, incremental steps are taken. When teams are comfortable with their understanding of the deployment, have gained operational expertise, and derived substantial value, another step toward a full mesh is usually accomplished. Since n ot all components of a full service mesh are helpful to teams based on their focus or current pain points, not all teams choose to take another step. This will evolve over time, as full service mesh deployments become ubiquitous. More than this, application developers and service (product) owners will begin to rely on the power of a service mesh to empower and satisfy their requirements as well.
Which applications should be constructed from the ground up or transformed using a new service mesh architecture depends on engineering maturity and skill set. You don't have to use all of the features; use the ones you need. Given that some service meshes provide a path to partial adoption, the best way may be to mitigate risk, baby-step it, and show incremental triumphs. Some service meshes can be deployed and digested in a single step. Even if this is the case, you might find that you enable only a subset of its capabilities. Presence of a service mesh’s capabilities is separate from whether those capabilities are actively engaged.
Observability is at the top of the list of reasons why most organizations deploy a service mesh initially. You usually obtain a service dependency graph in addition to metrics, logs, and traces. These graphs visually identify how much traffic is coming from one service and going to the next. You'll feel as if you're running blind if you don't have a visible topology or service graph.
Alternatively, it could be your current load balancer that is running blind. Most service mesh proxies will come in handy if you're running gRPC services and have a load balancer ignorant of gRPC and treats this traffic like any other TCP traffic. Modern service proxies will support HTTP/2 and, as such, might provide a gRPC bridge from HTTP/1.1 to HTTP/2.
Security
Organizations usually prioritise security last. They may not want strong authentication and encryption when they ultimately do look into security. Although it is best practise to secure everything using strongly authenticated and authorised services, some organisations fail to do so, resulting in soft, gooey centres in their microservices deployments. Some teams are content to secure the edge of their network, but they still want the observability and control that a service mesh can provide.
Needless to say, it is recommended that you run workloads securely, using a service mesh to provide authentication and authorization between all service requests.
Why aren't certain organizations interested in using Service Mesh's managed certificate authority? Because it is another thing to operate? When connections are established, encryption consumes resources (CPU cycles) and can inject a few microseconds of latency. Given this, and to aid adoption, some service meshes prominently display installation options that include a certificate authority (CA) and installation configurations that do not. Maybe you consider the “gooey center” of your mesh to be secure because there is little to no ingress/egress traffic to/from the cluster and access is provided only via VPN into the cluster. Depending on workload, wallet, and sensitivity to latency, you might find that you don’t want the overhead of running encryption between all of your services.
Maybe you're just searching for authorization checks, and you're deploying monoliths rather than microservices. You don't need any further monitoring integrations because you already have API management. Perhaps you use IP addresses (subnets) for network security zones. Using identities and encryption provided by the service mesh, together with authorization checks enforced by policy you specify, a service mesh can help you get rid of network partitions and firewalling on Layer 3 (L3) boundaries. You can flatten your internal network by policy enforcing, authorization checks across your monoliths, making services broadly reachable while granularly controlling which requests are authorized. The power of service mesh to analyse and reason over details of request traffic much beyond IP addresses and ports (Layer 3/4) provides significantly more flexibility.
Retrofitting a Deployment
Recognize that, while some greenfield projects may have the luxury of starting with a service mesh, most organizations will have existing services (monoliths or otherwise) to onboard to the mesh. These services could run in VMs or bare-metal hosts instead of containers. Fear not! Some service meshes squarely address such environments and help with the modernization of such services, allowing organizations to renovate their services inventory by:
- Not having to rewrite their applications
- Adapting microservices and existing services using the same infrastructure architecture
- Facilitating adoption of new languages
- Facilitating moving to or securely connecting with services in the cloud (or on edge)
For those organisations who adopt a strangler pattern of building services around a legacy monolith to expose a more developer-friendly set of APIs, service meshes make it easier to insert facade services as a way of breaking down monoliths.
With the adoption of a service mesh, organisations can get observability (e.g., metrics, logs, and traces) as well as dependency or service graphs for all of their services (micro or not). The only change required within the service with respect to tracing is to forward certain HTTP headers. With the least amount of code change, service meshes are effective for retrofitting uniform and ubiquitous observability tracing into existing infrastructures.