
Cloud Native Performance
Donated by Layer5, Intel, Red Hat, and HashiCorp, Cloud Native Performance is a CNCF-hosted project. MeshMark provides a universal performance index to gauge your infrastructure's efficiency against deployments in other organizations' environments.
Standardizing Cloud Native Value Measurement
SMP is a collaborative effort of Layer5, UT Austin, Intel, Red Hat, HashiCorp, Google and The Linux Foundation.
Performance of Envoy Filters
The following analysis compares native Envoy filter performance to WebAssembly (WASM) filter performance using Rust.


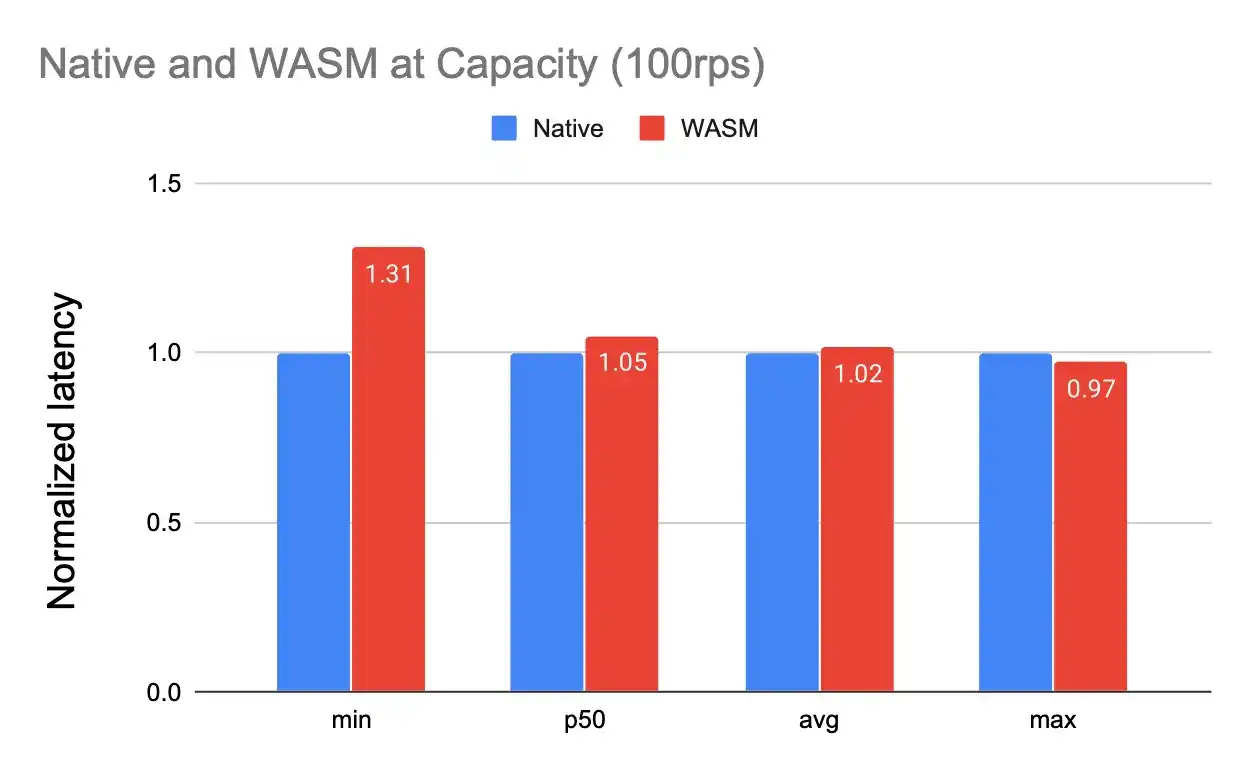
Native WASM at Capacity
When every request goes via the rate-limit check and then the actual program logic, we see that the latency incurred for the WASM code is higher than the Native client. This is expected since the native client has processing for rate-limiting locally in a process whereas the rust module is invoked as an additional thread to do the processing and the communication involved with the module incurs an overhead. This is prominent in the minimum response time case which represents latency just due to rate-limiting logic where every other part of the request is already "warm".
As we move towards average latency, the overhead gets slightly amortized but is still above the native rate-limiting case. Our max latency is slightly lower than native, but we attribute it to various other system effects like TLS handshake and network latencies that usually contribute to the maximum tail latency.
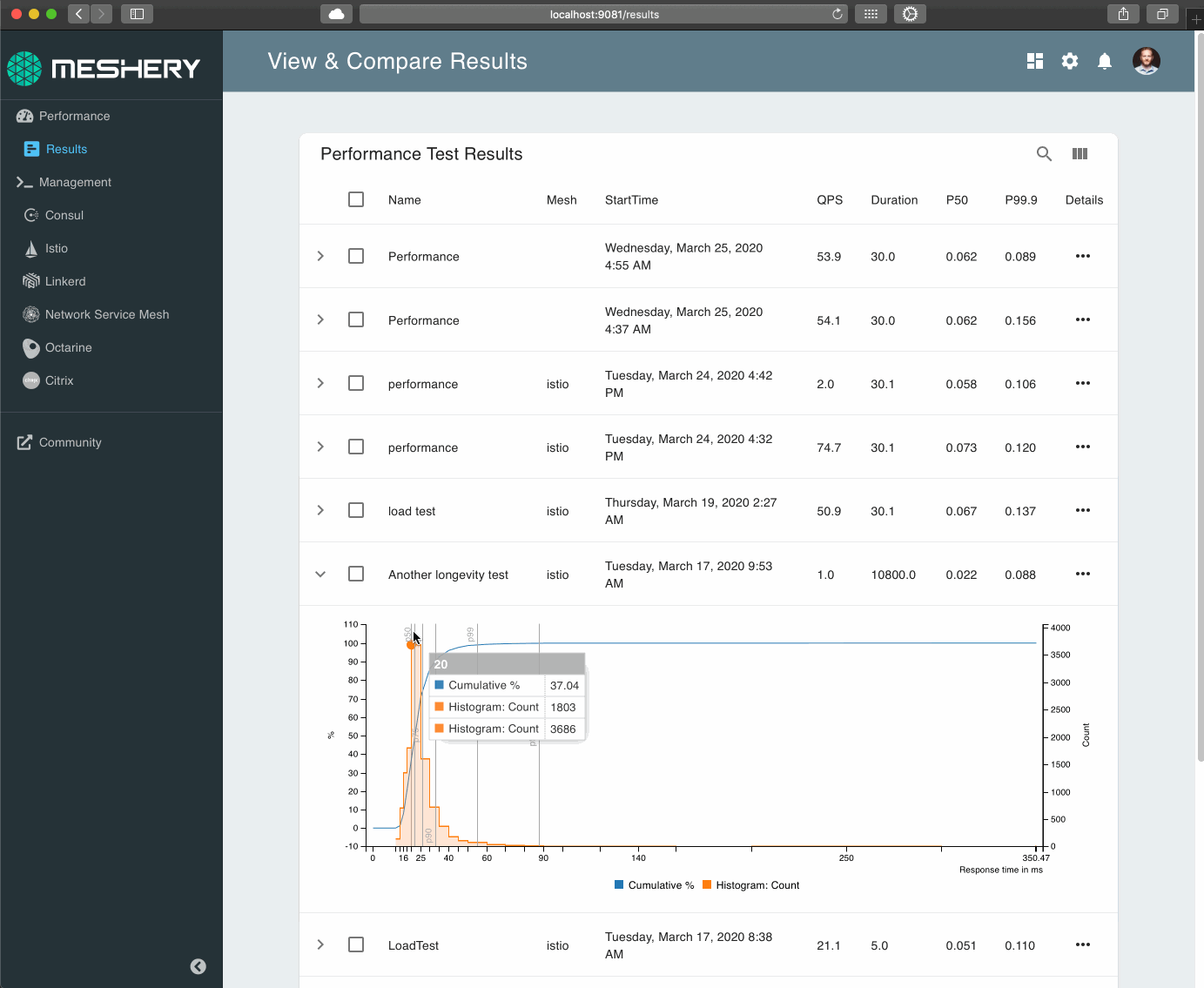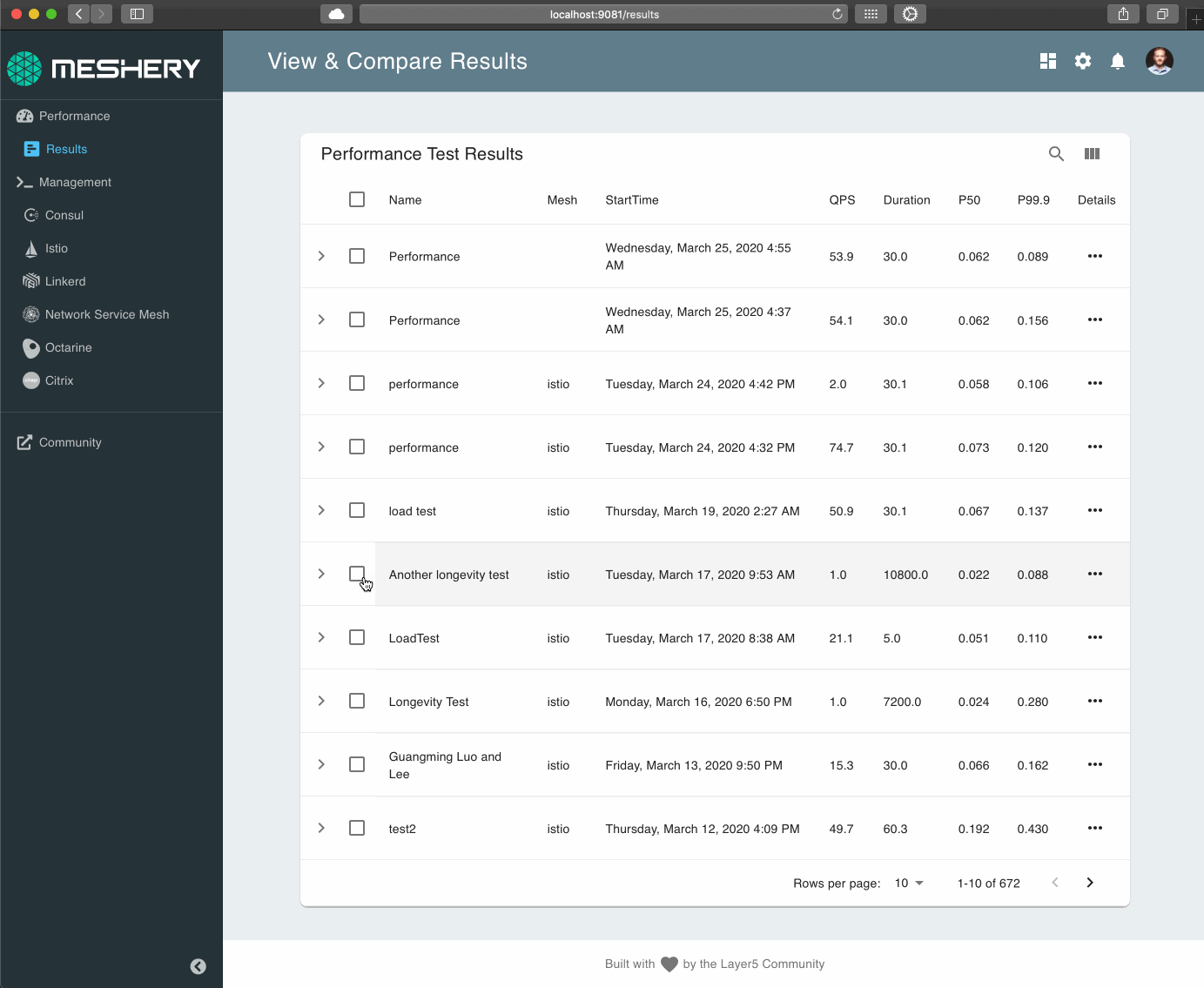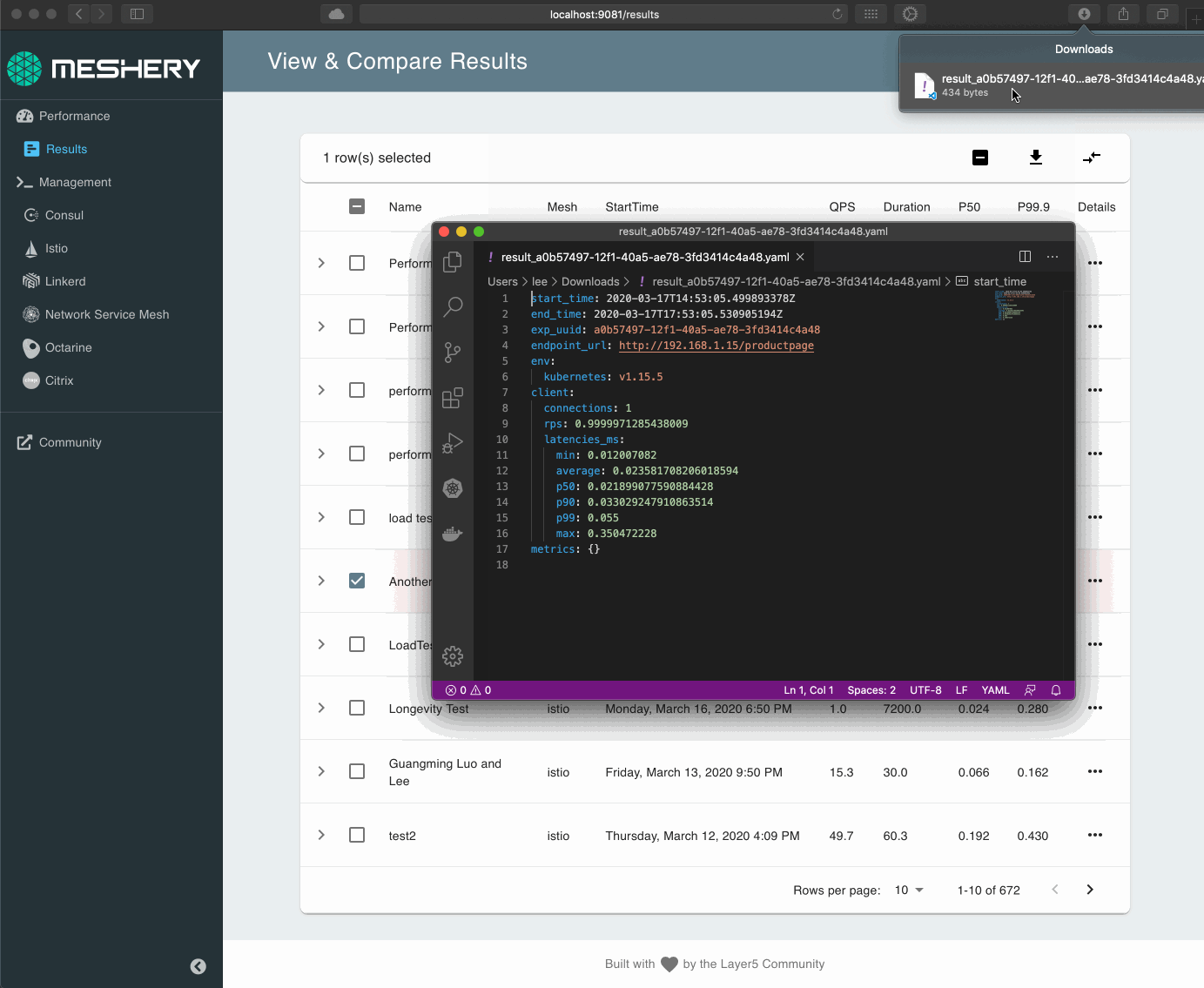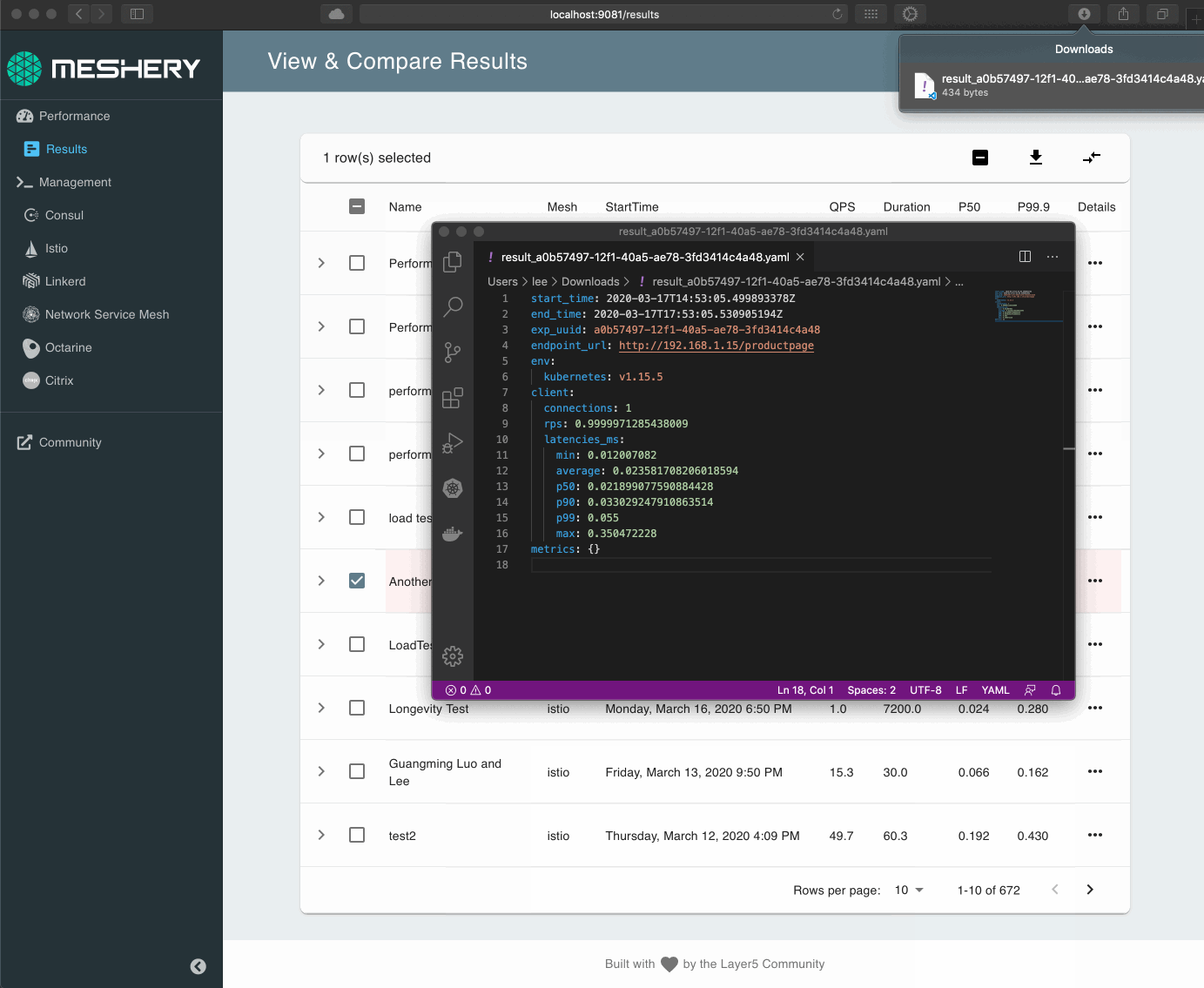
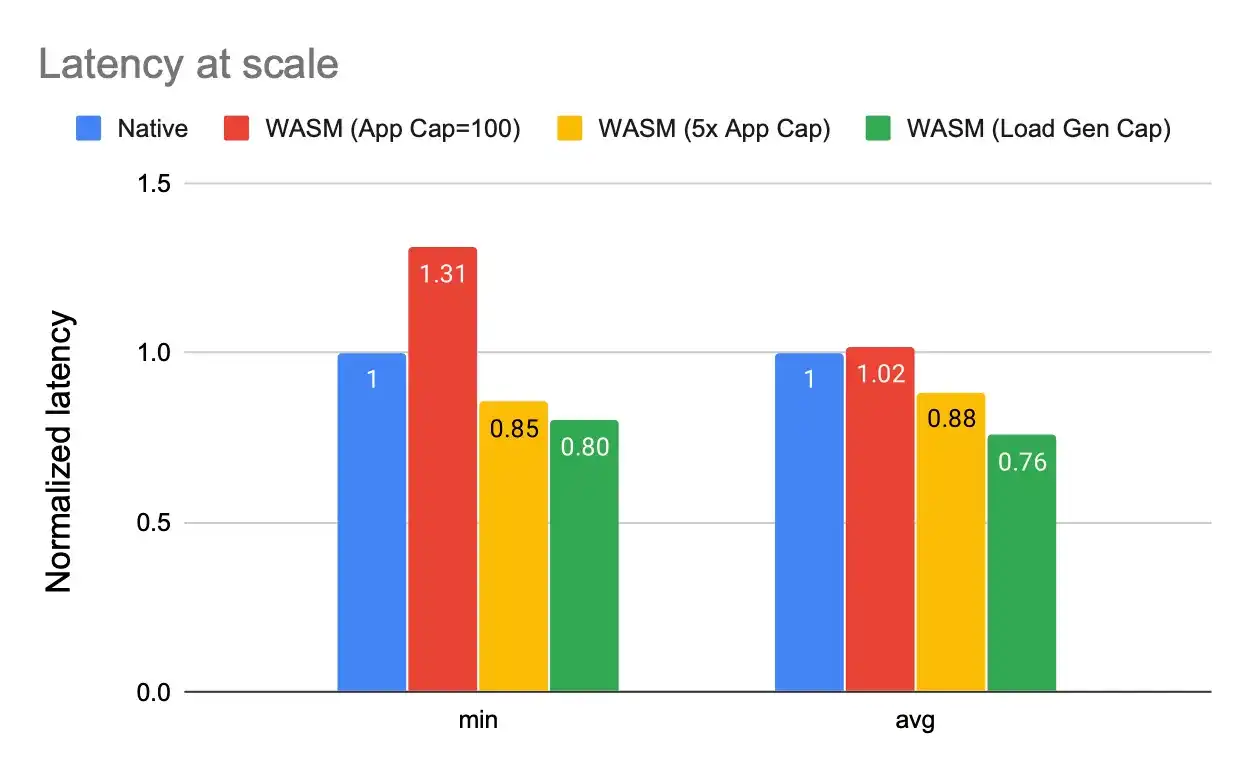
Latency at scale
When we go beyond the application capacity (100 in our example), we start noticing the power of a in-line ight wasm module which starts terminating requests at the side-car and the core application logic is never invoked/loaded. We notice that even the minimum response time for a terminated request is about 15-20% faster than invoking of application logic since the wasm is a dynamic module in the sidecar and we start to avoid complex network redirection and invocation of a new container/instance. We also notice that the average latency of requests is lower than in the case of native client.



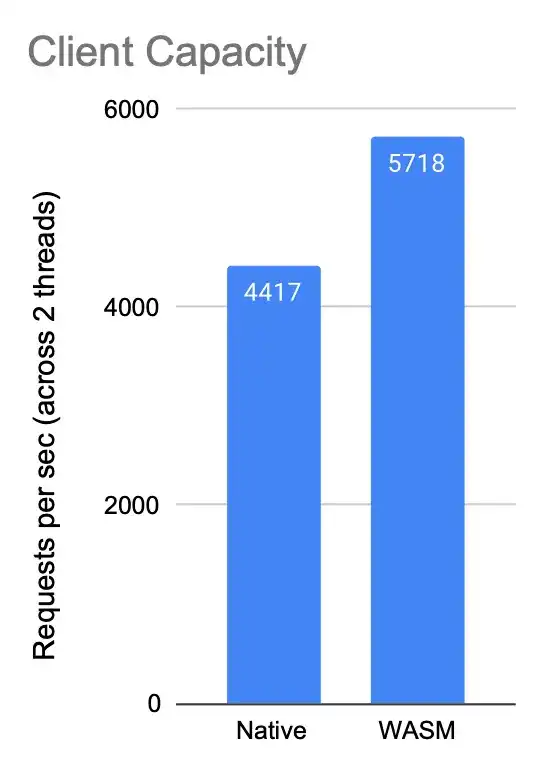
Client Capacity
Client Capacity figure also shows us that we are able to handle more requests than in the native case, although this infometric needs to be taken with a grain of salt, i.e. the difference might reduce if our application capacity was significantly larger than 100.
Discreetly Studying the Effects of Individual Traffic Control Functions
The group is also working in collaboration with the Envoy project to create easy-to-use tooling around distributed performance management (distributed load generation and analysis) in context of Istio, Consul, Tanzu Service Mesh, Network Service Mesh, App Mesh, Linkerd, and so on.










